
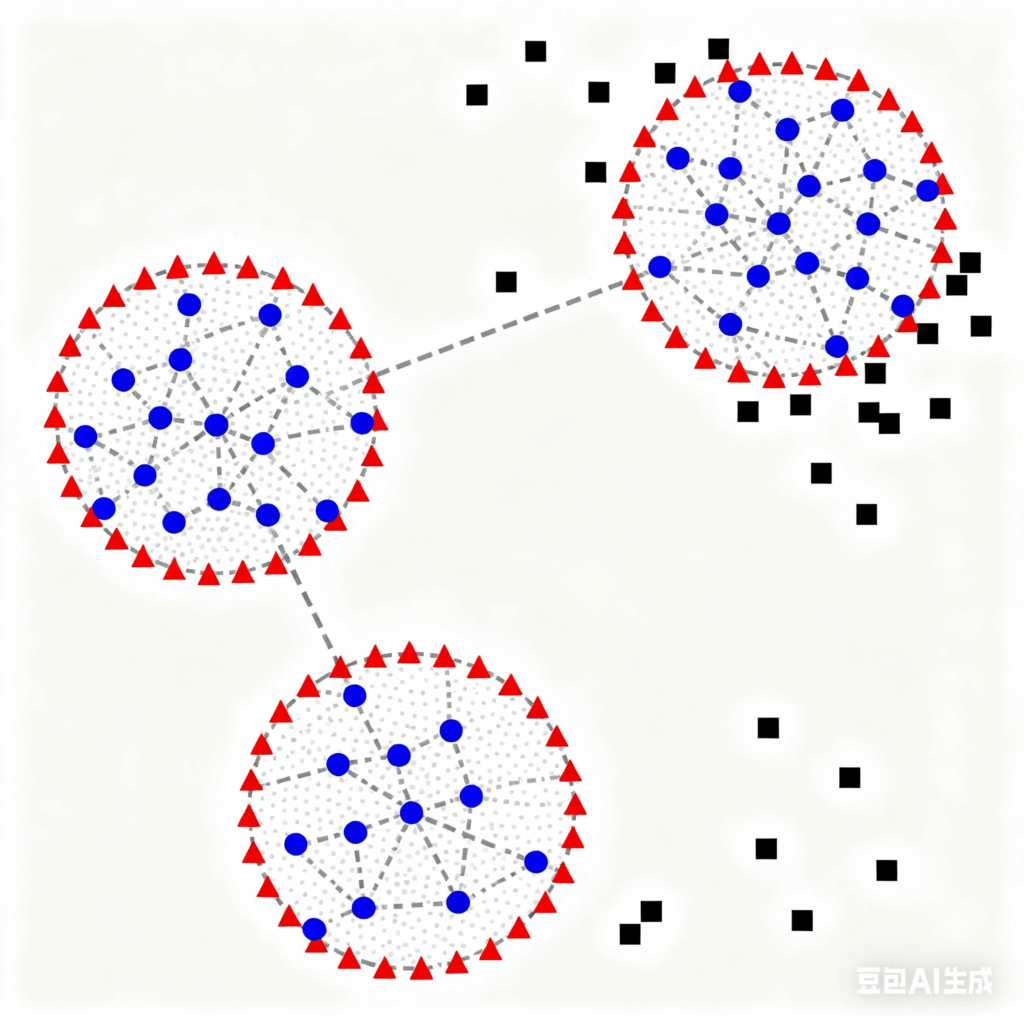
简介
DBSCAN 算法的全称是 “Density-Based Spatial Clustering of Applications with Noise”,中文意为 “基于密度的带有噪声的空间聚类应用”。DBSCAN是一种基于密度的聚类算法,核心是将 “密度相连” 的样本聚成一类,能自动识别任意形状的簇并标记噪声点。
相关概念
- ε(Epsilon):定义 “样本的邻域范围”,即某个样本周围多大范围内的其他样本会被视为 “邻居”。
- MinPts(Minimum Points):定义 “密集的标准”,即一个邻域内至少包含多少个样本,才能被判定为 “密集区域”
- 密度可达:通过核心点的 ε 邻域间接连接的样本
- 三种类型的点:
算法流程
步骤 1:初始化标记,遍历未处理样本
- 给所有样本打上 “未访问” 标记,确保每个样本都会被检查;
- 从第一个 “未访问” 的样本开始,进入后续判断;处理完一个样本后,继续遍历下一个 “未访问” 样本,直到所有样本都被标记。
步骤 2:判断当前样本类型,区分核心点与非核心点
- 计算当前 “未访问” 样本的 ε 邻域内,所有其他样本的数量(即 “邻居数”)。
- 若邻居数 ≥ MinPts:该样本是核心点,进入 “扩展簇” 步骤;若邻居数 < MinPts:暂时标记为 “未分类”,先跳过,后续由核心点判断是否为边界点。
步骤 3:从核心点出发,扩展密度相连的簇
这是形成簇的关键步骤,核心是把所有 “密度可达” 的样本归为同一簇。
- 以当前核心点为起点,创建一个新的簇,并将该核心点加入簇中,同时标记其为 “已访问”。
- 收集该核心点 ε 邻域内的所有样本,作为 “待检查邻居列表”。
- 遍历 “待检查邻居列表” 中的每个样本:
- 直到 “待检查邻居列表” 为空,当前簇扩展完成,簇数量 + 1。
步骤 4:标记噪声点,完成所有聚类
- 所有样本遍历结束后,未被加入任何簇的 “未分类” 样本,即为噪声点,直接标记为 “噪声”。
- 最终就可以得到所有簇(包含核心点和边界点)和噪声点的标记结果。
python代码实现
输入
- 第一行输入三个数 eps、min_samples、x,以空格隔开,分别表示:
- 第二行开始为输入的样本数据,数值之间用空格隔开,共输入 x 行,每行输入的数值数量为 y 个,且满足 2≤y≤3。
输出
输出两个值,用空格隔开:
- 第一个值:得到的簇的个数。
- 第二个值:识别到的噪声点的个数。
示例
输入示例1:
|
1 2 3 4 5 6 7 8 9 10 11 |
2 2 10 0 0 3 3 6 6 9 9 12 12 2 6 6 2 9 5 5 9 10 2 |
eps为2,min_samples为2,共10个点。
输出示例1:
0 100个簇,10个噪声点。
完整代码
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 |
def read_input(): # 读取用户输入的一行字符串 eps, min_samples, x = map(float, input().split()) min_samples = int(min_samples) x = int(x) samples = [] for _ in range(x): # 读取用户输入的下一行字符串 samples.append(list(map(float, input().split()))) return eps, min_samples, x, samples def distance(sample_a, sample_b): return sum([(ai - bi) ** 2 for ai, bi in zip(sample_a, sample_b)]) def get_cluster(i, eps, samples, visited): neighbors = [] for j in range(len(samples)): if visited[j]: continue if distance(samples[i], samples[j]) <= eps * eps: neighbors.append(j) visited[j] = True return neighbors def dbscan(eps, min_samples, x, samples): clusters_num = 0 visited = [False] * x noise = [True] * x for i in range(x): if visited[i]: continue cluster = get_cluster(i, eps, samples, visited) samples_in_cluster = [] while cluster: j = cluster.pop() samples_in_cluster.append(j) cluster.extend(get_cluster(j, eps, samples, visited)) if len(samples_in_cluster) >= min_samples: clusters_num += 1 for p in samples_in_cluster: noise[p] = False return clusters_num, sum(noise) if __name__ == '__main__': eps, min_samples, x, samples = read_input() clusters_num, noise_num = dbscan(eps, min_samples, x, samples) print(clusters_num, noise_num) |
参考
- https://zhuanlan.zhihu.com/p/1925351611942809908
- sklearn官方文档